Example-driven Virtual Cinematography by Learning Camera Behaviors
HONGDA JIANG^ —— CFCS, Peking University & AICFVE, Beijing Film Academy
BIN WANG^ —— AICFVE, Beijing Film Academy
XI WANG —— University Rennes, Inria, CNRS, IRISA & AICFVE, Beijing Film Academy
MARC CHRISTIE —— University Rennes, Inria, CNRS, IRISA & AICFVE, Beijing Film Academy
BAOQUAN CHEN* —— CFCS, Peking University & AICFVE, Beijing Film Academy
(^ equal contribution, * corresponding author)
We propose the design of a camera motion controller which has the ability to automatically extract camera behaviors from different film clips (on the left) and re-apply these behaviors to a 3D animation (center).
Abstract
Designing a camera motion controller that has the capacity to move a virtual camera automatically in relation with contents of a 3D animation, in a cinematographic and principled way, is a complex and challenging task. Many cinematographic rules exist, yet practice shows there are significant stylistic variations in how these can be applied. In this paper, we propose an example-driven camera controller which can extract camera behaviors from an example film clip and re-apply the extracted behaviors to a 3D animation, through learning from a collection of camera motions.
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2020)
Demo
Method
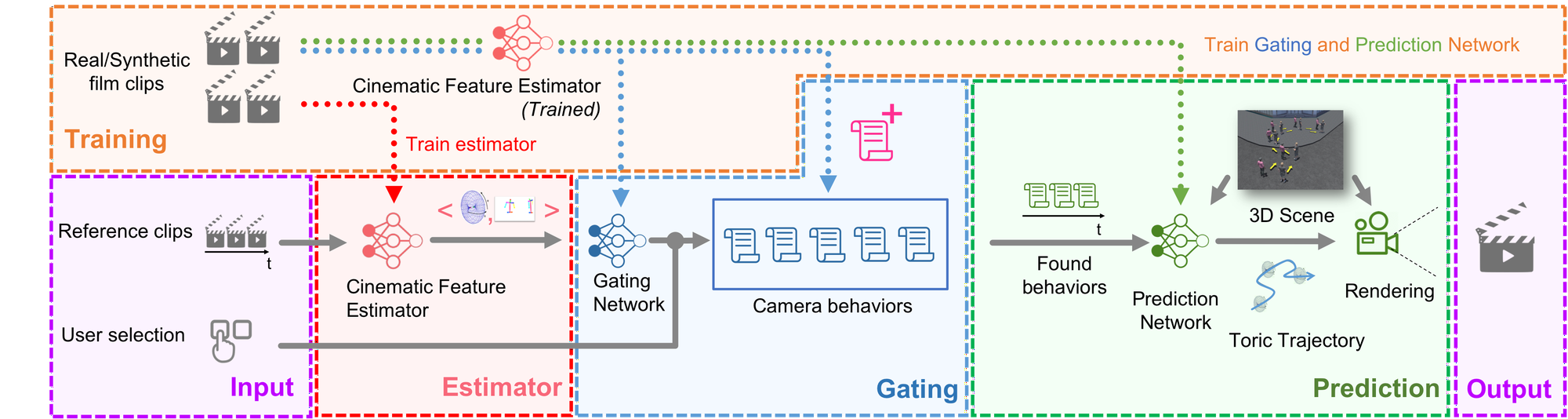
Our proposed framework for learning camera behaviors composed of a Cinematic Feature Estimator which extracts high-level features from movie clips, a Gating network which estimates the type of camera behavior from the high-level features, and a Prediction network which applies the estimated behavior on a 3D animation.
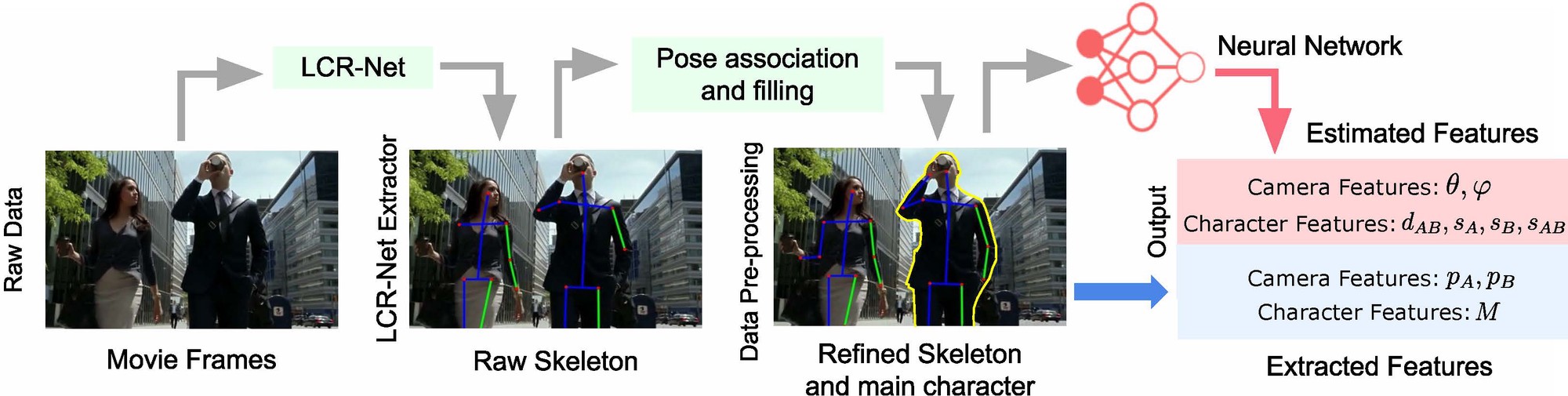
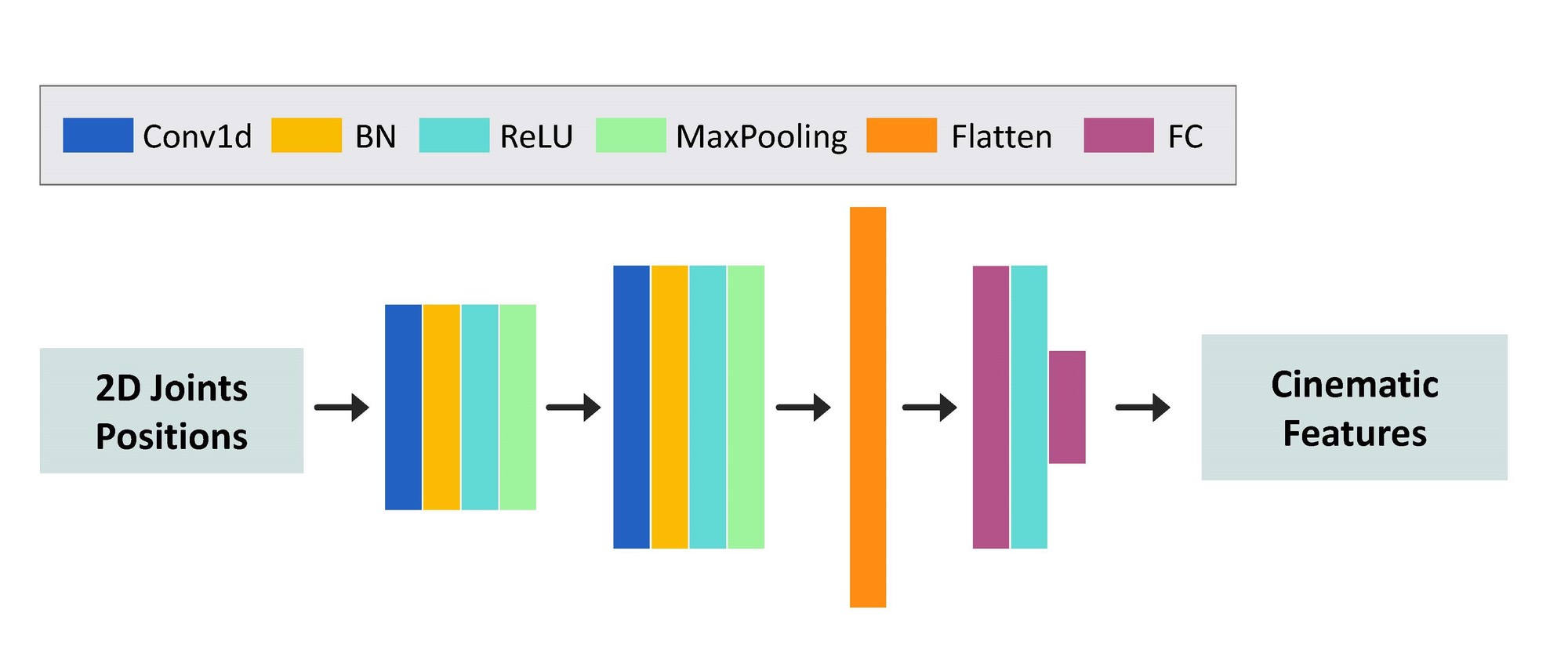
To estimate cinematic features from film clips, each frame should pass through the following steps: (i) extracting 2D skeletons with LCR-Net, (ii) pose association, filling missing joints and smoothing, and (iii) estimating features through a neural network.
Learning stage of the Cinematic Feature Estimator. Input data is gathered over on a sliding window of $t_c=8$ frames to increase robustness during the learning and testing phases. The output data gathers cinematic features such as the camera pose estimation in Toric space and character features.
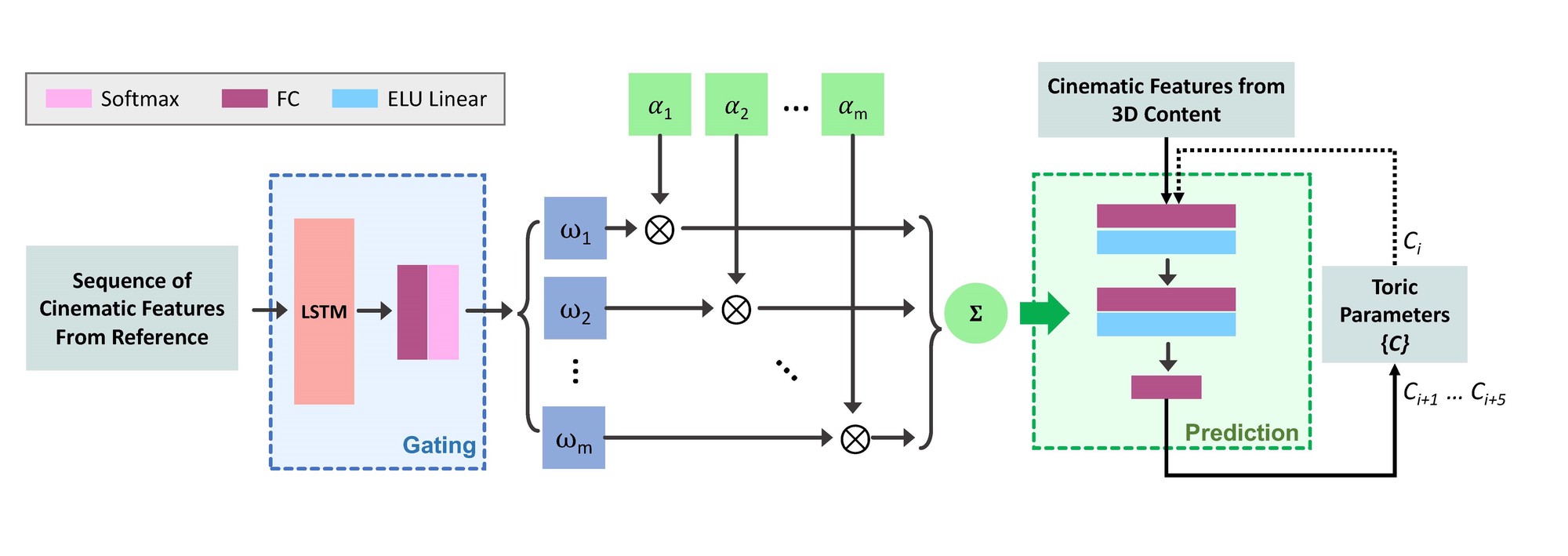
Structure of our Mixture of Experts (MoE) training network. The network takes as input the result of the Cinematic Feature Estimator applied on reference clips and the 3D animation. It outputs a sequence of camera parameters for each frame of the animation that can be used to render the animation.
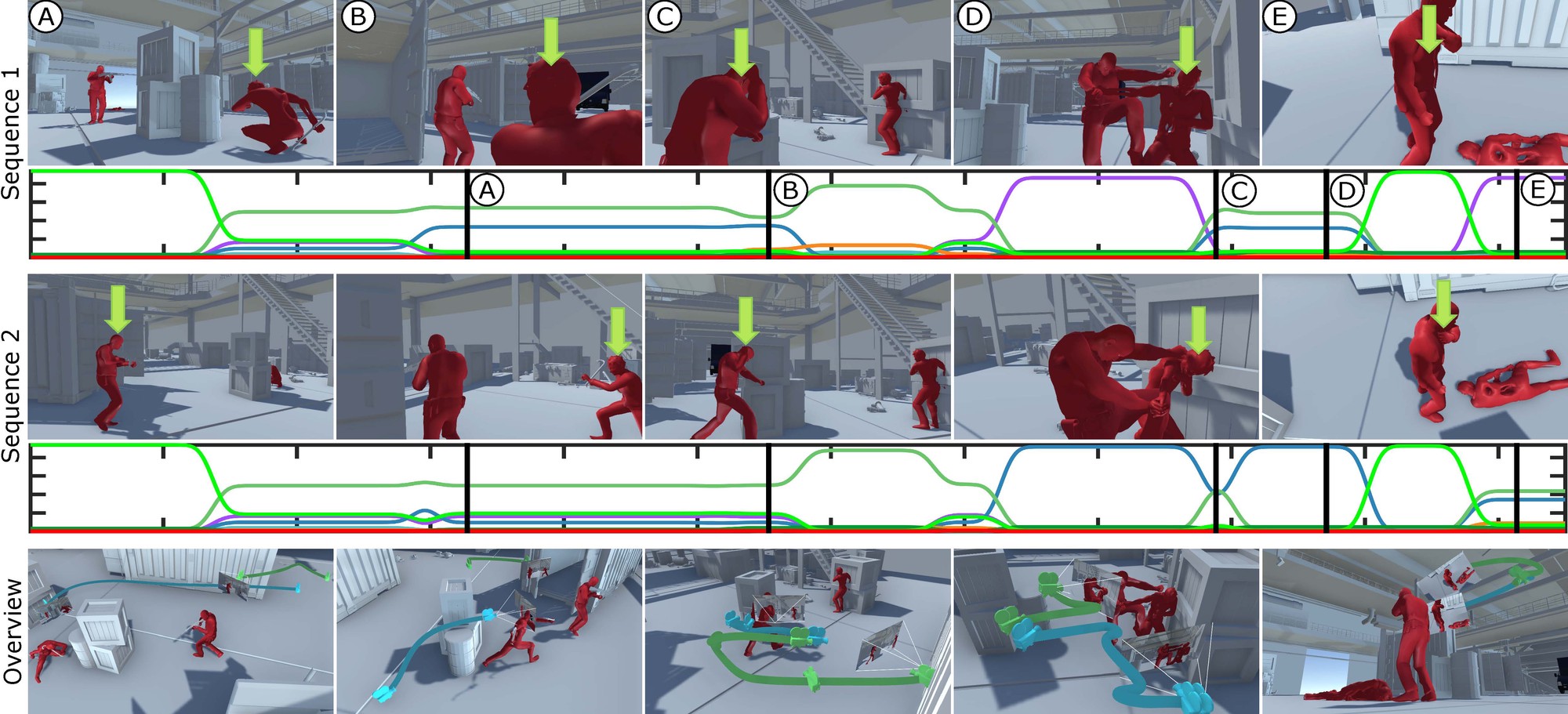
Side track with different main character. In side track mode, the camera will always look from one side of the main character no matter his/her facing orientation. Green arrow indicates the main character in each sequence.
Relative vs direct track with same main character. Relative track (top) puts more emphasis on the male character; while the feeling conveyed by direct track (bottom) is more objective. Green arrow indicates the main character in each sequence.
Snapshots taken from two distinct camera motions computed on the zombie sequence using two distinct sequences of input. The green arrow represents the main character. As viewed in the snapshots, there are changes in the main character throughout the sequence. This enables the designer, through selected clips, to emphasize one character over another at different moments.
Bibtex
TBD
Acknowledgement
This work was supported in part by the National Key R&D Program of China (2018YFB1403900, 2019YFF0302902). We also thank Anthony Mirabile and Ludovic Burg from University Rennes, Inria, CNRS, IRISA and Di Zhang from AICFVE, Beijing Film Academy for their help in animation generation and rendering.
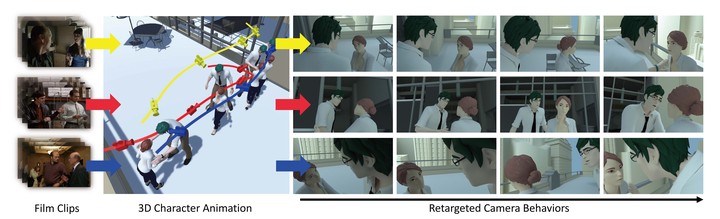 We propose the design of a camera motion controller which has the ability to automatically extract camera behaviors from different film clips (on the left) and re-apply these behaviors to a 3D animation (center).
We propose the design of a camera motion controller which has the ability to automatically extract camera behaviors from different film clips (on the left) and re-apply these behaviors to a 3D animation (center).